Kimono von kimonolabs bietet eine benutzerfreundliche Möglichkeit, Webseiteninhalte strukturiert abzugreifen. So lassen sich ohne Programmierkenntnisse große Textsammlungen anlegen. Besonders sinnvoll erscheint dieser Service auch, wenn Webseiten keine API (dt. Programmierschnittstelle) anbieten, um Daten auf komfortablen Weg zu übertragen. Man baut sich einfach seine eigene API und erhält als Output eine JSON-, RSS- oder CSV-Datei mit dem gewünschten Text der Website.
Bookmarklet oder Chrome Plugin
![]() Um Kimono nutzen zu können, braucht es einen Login. Außerdem müssen wir ein Bookmarklet in unserem Browser einrichten oder das hauseigene Google Chrome Plugin von Kimono installieren. Nach dem Klick auf das Bookmarklet oder den Plugin-Button gelangt man auf eine zwischengespeicherte Version der Webseite, auf die sich das Kimono-Interface legt.
Um Kimono nutzen zu können, braucht es einen Login. Außerdem müssen wir ein Bookmarklet in unserem Browser einrichten oder das hauseigene Google Chrome Plugin von Kimono installieren. Nach dem Klick auf das Bookmarklet oder den Plugin-Button gelangt man auf eine zwischengespeicherte Version der Webseite, auf die sich das Kimono-Interface legt.
Linkliste erstellen
Alle Elemente, die der Webscraper speichern kann, sind auf der Webseite nun anklickbar. Wählt man ein Kochrezept in einer Liste von Rezepten aus, erkennt Kimono alle anderen Rezept-Links in der Spalte und fragt, ob diese in die Auswahl übernommen werden sollen.
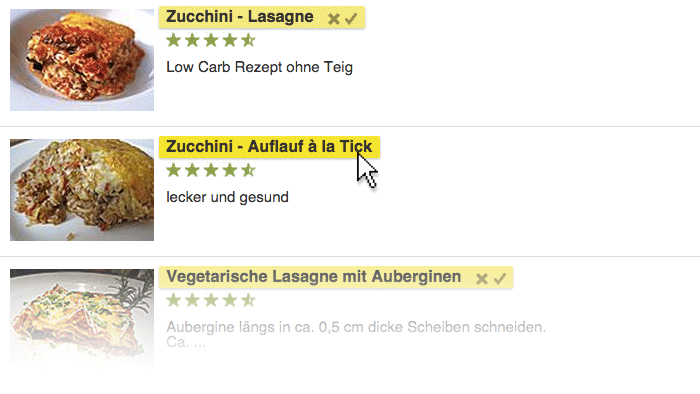 Anschließend gibt man dem Datenfeld (Kimono nennt es Properties) einen Namen: Rezept-Link. Kimono speichert hierbei automatisch nicht nur den Namen des Kochrezepts – also den Text im HTML-Block A – sondern auch die Link-URL – also die Webadresse zum Kochrezept selber im „src“-Attribut des A-Blocks.
Anschließend gibt man dem Datenfeld (Kimono nennt es Properties) einen Namen: Rezept-Link. Kimono speichert hierbei automatisch nicht nur den Namen des Kochrezepts – also den Text im HTML-Block A – sondern auch die Link-URL – also die Webadresse zum Kochrezept selber im „src“-Attribut des A-Blocks.
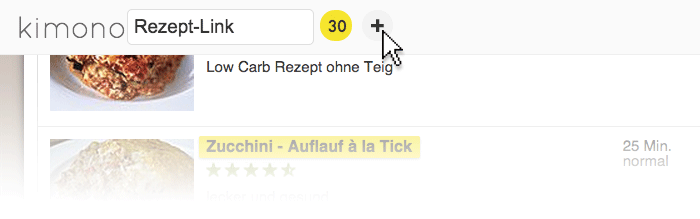
Dieser Schritt ist beliebig oft wiederholbar. So können wir nicht nur den Verweis zu einem Kochrezept speichern, sondern beispielsweise auch das jeweilige Bild zum Kochrezept, sofern es in die selbe HTML-Struktur eingebettet ist. Doch zunächst lassen wir nur eine Liste mit Links zu Kochrezepten zusammenstellen.
Pagination
Hat man ausgewählt, welche Elemente auf einer Webseite gespeichert werden sollen, bietet Kimono uns im nächsten Schritt ein Feature an, das den Scraper die Pagination oder Blätterfunktion von Webseiten bedienen lässt. Wir wählen das Buch-Icon aus und klicken auf unserer Webseite auf den Link, mit Hilfe dessen wir zur nächsten Seite gelangen („Weiter“, „Nächste Seite“ etc.). Weiß Kimono, wie man auf die nächste Seite gelangt, bahnt es sich einen Weg durch die Rezept-Community später von allein und kann so beliebig viele Seiten scrapen.
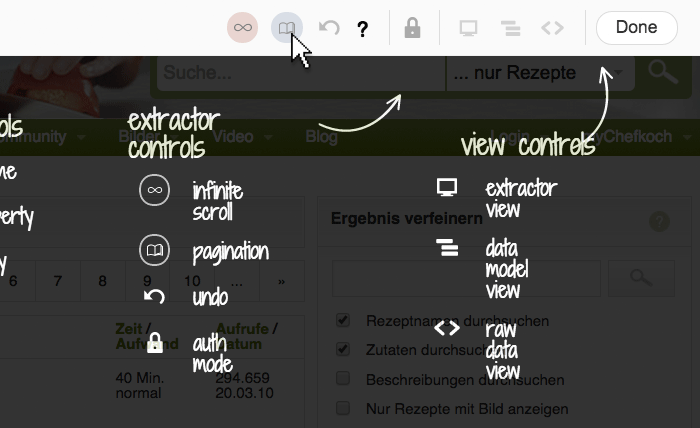
Auch mit sogenannten infinite scroll-Systemen, bei denen neuer Seiteninhalt mittels Javascript unterhalb der selben Webseite nachgeladen wird (z.B. wie bei Tumblr), kann Kimono umgehen.
Um an große Datensätze zu gelangen, erweist sich die Blätterfunktion von Kimono als hilfreich.
Scrapen nach Login
Sollte ein Login für den Einsatz des Webscrapers erforderlich sein, händelt Kimono dies für uns im Auth mode. Hierzu muss das Chrome Plugin für den Inkognito-Modus zugelassen sein.
API speichern
Zum Abschluss schalten wir in einen zweiten Bildschirm, der uns den Webscraper im Detail konfigurieren lässt. Pro-Tipp: Hier kann der CSS-Pfad oder Regular Expressions-String für jedes zu speichernde Feld noch einmal angepasst werden (um etwa komplexere Datenstrukturen abzugreifen). In den meisten Fällen können diese Felder aber unverändert bleiben. Am Ende liefert Kimono uns eine Vorschau des Outputs im JSON-, CSV- oder RSS-Format. Nach dem Klick auf Done gibt man der API einen Namen und wählt ein Zeitintervall für das Scrapen aus. Wir nennen unsere API Rezepte.
APIs kombinieren
Kimono kann APIs miteinander kombinieren. So haben wir im ersten Schritt eine API erstellt, die Rezept-Links sammelt. Im zweiten Schritt erstellen wir eine weitere API, die jeden einzelnen Rezept-Link auflöst, die entsprechende Webseite scannt und das Kochrezept herunterlädt. Hierzu müssen wir Kimono wieder mitteilen, welche Felder gespeichert werden sollen. Wir surfen auf eine beliebige Rezeptseite, auf der eine Kochanweisung und eine Zutatenliste zu lesen sind und merken uns diese Felder fürs Speichern vor. Wir nennen unsere zweite API Rezept-Details.
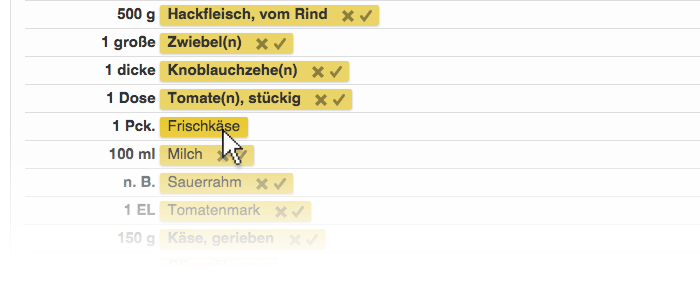
Nachdem wir unsere zweite API erstellt haben, kombinieren wir sie mit der Ersten. Hierzu rufen wir im Login-Bereich von Kimono die Seite My APIs auf, die uns eine Übersicht unserer APIs liefert. Wir wählen die zuletzt erstellte API (Rezept-Details) aus und legen unter Crawl Setup, im Feld Source API unsere erste API (Rezepte) fest. Klickt man auf Start Crawl, beginnt Kimono alle Rezept-Texte, die wir mit unserer ersten API indiziert haben, herunterzuladen. Unter dem Reiter Data preview erhalten wir wieder eine Vorschau auf unsere gesammelten Daten im CSV-, RSS- oder JSON-Format.
Am Ende haben wir ein Korpus aus Tausenden von Kochrezepten. Mit dieser Textsammlung können wir nun weiterarbeiten, sie sortieren, rearrangieren, nach Regeln parsen oder transformieren – etwa mit einem Python-Script oder durch eine Konkordanzsoftware. Wie man das macht, beschreiben wir ein andermal.

- Chicken Infinite
- Gregor Weichbrodt
- 2014
- 654101 Zeichen
- Download: pdf