Kimono by kimonolabs offers a user-friendly method for grabbing the contents of websites in a structured way. Without needing to know anything about programming, you can compile enormous collections of texts. This service is especially useful when websites do not offer APIs, that is, interfaces with which one can gather data directly (as does Twitter). Instead, you build your own API with Kimono, and get as output a JSON, RSS, or CSV file that contains the text from the particular website.
Bookmarklet or Chrome plugin
![]() In order to be able to use Kimono, you need to create a username and log in. Additionally, you need to install a browser bookmarklet or use the Google Chrome plugin for Kimono. After clicking the bookmarklet or the plugin button, you see a cached version of the website and a layer with the Kimono interface.
In order to be able to use Kimono, you need to create a username and log in. Additionally, you need to install a browser bookmarklet or use the Google Chrome plugin for Kimono. After clicking the bookmarklet or the plugin button, you see a cached version of the website and a layer with the Kimono interface.
Creating a list of links
All elements the web scraper can grab are now clickable. If you chose a recipe from a list (like in the image below), Kimono automatically recognizes all other recipe links in the same column and asks whether it should select them as well.
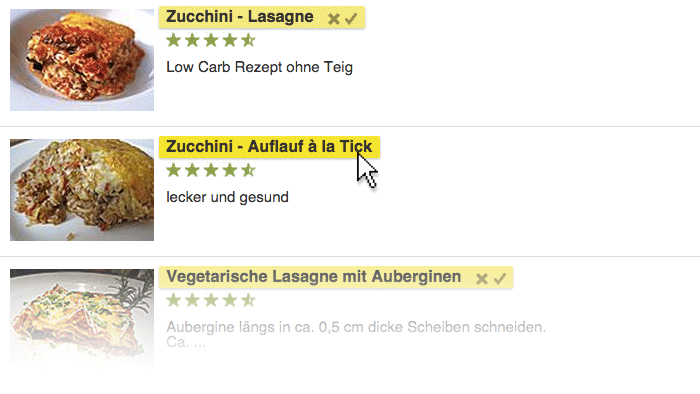 Once you have selected everything you need, you give the data field (the output, which Kimono calls properties) a name: Recipe_Link. Kimono saves not only the name of the recipe (the HTML block) but also the URL (the link to the actual recipe in the “src” attribute of the block).
Once you have selected everything you need, you give the data field (the output, which Kimono calls properties) a name: Recipe_Link. Kimono saves not only the name of the recipe (the HTML block) but also the URL (the link to the actual recipe in the “src” attribute of the block).
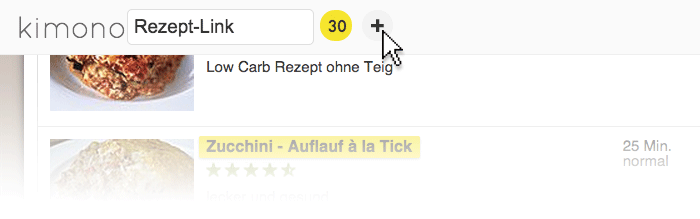
You can repeat this step as often as you like. This way, you can save not only the link to the recipe but also, say, to the image associated with it, as long as it is part of the same HTML structure. For now, let’s just compile a list of links to the recipes.
Pagination
Once you have selected the elements of a website you want to save, as a next step Kimono offers a neat function that allows you to extend the selection to the following pages by finding the “next page” link. You do this by first clicking the pagination button (the book icon) and then clicking the link to the next page. As soon as Kimono knows how to get to the next page, it automatically finds its way through the myriad recipes that follow. This way, you can scrape as many pages as you like.
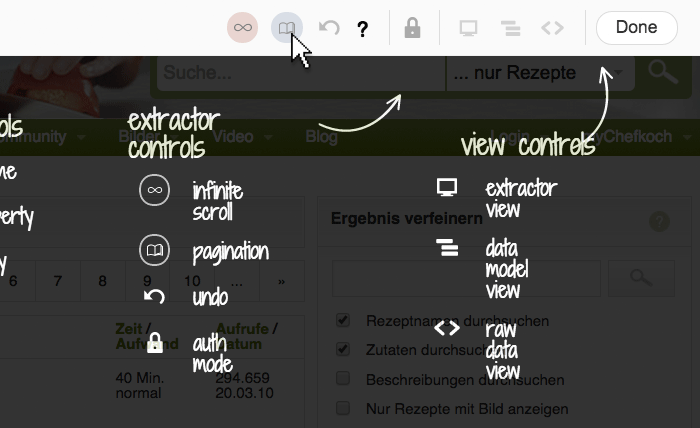
It can even deal with infinite scroll systems in which the content is reloaded via JavaScript at the bottom of the page once you scroll down (like in Tumblr).
The pagination function is the key to assembling large data sets.
Scraping after a login
Should you need to log into a page before you can scrape it, Kimono can switch to what it calls Auth mode. You need to allow the Chrome plugin to operate in incognito mode. Kimono will save the user name and password and log in automatically.
Saving the API
As a last step, you will reach a second screen that lets you configure the details of the web scraper. Here, you can adjust the CSS path or the regular expressions string for each field you want to save (if you want to scrape more complex data structures). In most cases, you can leave everything as it is. Finally, you will see a preview of the output in either JSON, CSV or RSS format. Click Done, give the API a name, a chose a time interval for the scraping process. Our API is called recipes, and we’ll scrape only once.
Combining APIs
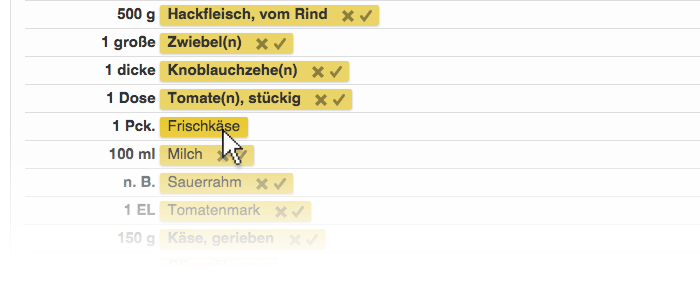
Kimono can combine APIs. Our first API collected links; but we can build a second one that resolves every individual recipe link, scans the fields in the target URL, and downloads the actual recipe. We only need to tell Kimono which fields to save. Starting from any recipe page that includes an ingredients and a recipe field, and select both fields for extraction. This second API we call Recipe_Details.
After having created the second API, you can combine it with the first. You do this by logging in to Kimono and going to the My APIs section, which shows a list of all the APIs you have built. You click your latest API (Recipe_Details), navigate to Crawl Setup, and select your first API (Recipe_Link) in the field Source API. After clicking Start Crawl, Kimono will download all the recipes you have identified with your first API. Clicking on the tab Data Field shows shows you a preview of the data collection in JSON, RSS, or CSV format.
Now, you have a corpus of thousands of recipes. You can continue to process further – to sort, rearrange, parse or transform your corpus – according to certain rules, for instance with a Python script or with a concordance software. We will show you how to do this another time.